AI Models for Pokemon Games
Pokemon offers a framework to think about virtual worlds that are microcosms of our own: they allow for open-ended discovery, present the player challenges which must be overcome, and ultimately, should be fun. The Pokemon games have been a mainstay of popular culture since 1996 (longer than I’ve been around) and have been played by hundreds of millions of people. And now, they are being played by AI agents.

As we move towards AI which is able to interact with and perform tasks for humans in real world – one which is open-ended, challenging, and fun – we’ve moved the agents from their own little boxes (Atari, Go, and chess) into games which begin to represent the breadth of our own world. Before they can take on the challenges of scientific discoveries, we’ll task the agents pursuing exploration and novelty in childhood games of fun.
Playing Pokemon games
In the mainline Pokemon games, players may have two main objectives:
-
Completing the gym challenge: the player progresses through the main story – fighting the eight gym leaders, elite four, and the champion – while defeating evil and saving the world in the process.

-
Gotta catch em all: the player does what they want! They can complete the Pokedex (catch ‘em all), fulfill side quests, train their Pokemon for the Olympics, teach their Pokemon to dance, hunt for rare shiny Pokemon – or any other sort of self-motivated objective.
With respect to (1), recently both Gemini 2.5 Pro (with significant prompt shaping) and Peter Whidden et al. 2025 (with significant reward shaping) have managed to play the original games, Pokemon Red and Blue, starting from scratch and completing the gym challenge: a significant milestone for reinforcement learning.
What makes Pokemon hard?
First and foremost, Pokemon is a long-horizon problem (some 25 hours for a human, many hundreds for Gemini) with a large action space $|A|$. At any given point in time, the player can talk to any number of non-playable characters (NPCs), explore houses, check out new areas, solve puzzles, level up their Pokemon, buy items, search for new Pokemon, …, the list goes on. By the curse of dimensionality, with respect to the horizon length $T$, this is immediately exponentially difficult $O(|A|^T)$. So there are a tremendous number of possible outcomes to explore.
This then presents a significant exploration challenge: the games can require you to be very surprising leaps – including for a human! – in order to progress, and in fact many of the older games were frequently sold with guides to tell you how to play. For example, in Pokemon Emerald, after defeating Norman in Petalburg Gym, the story requires you to backtrack to an easily-missed doorway in the Jagged Pass to discover Team Magma’s secret base – an easily missed location which you likely passed hours ago. Our models must therefore be able to make progress with sparse reward signals.
Finally, the raw battling mechanic is quite difficult. Within the battles, there is hidden information and delayed rewards. Picking Pokemon to even use on the team (team building) is a combinatorial design space. In more difficult game modes (competitive Pokemon, nuzlockes, or Radical Red), every battle becomes a puzzle or a match against an opponent – presenting a wide avenue for skill expression.
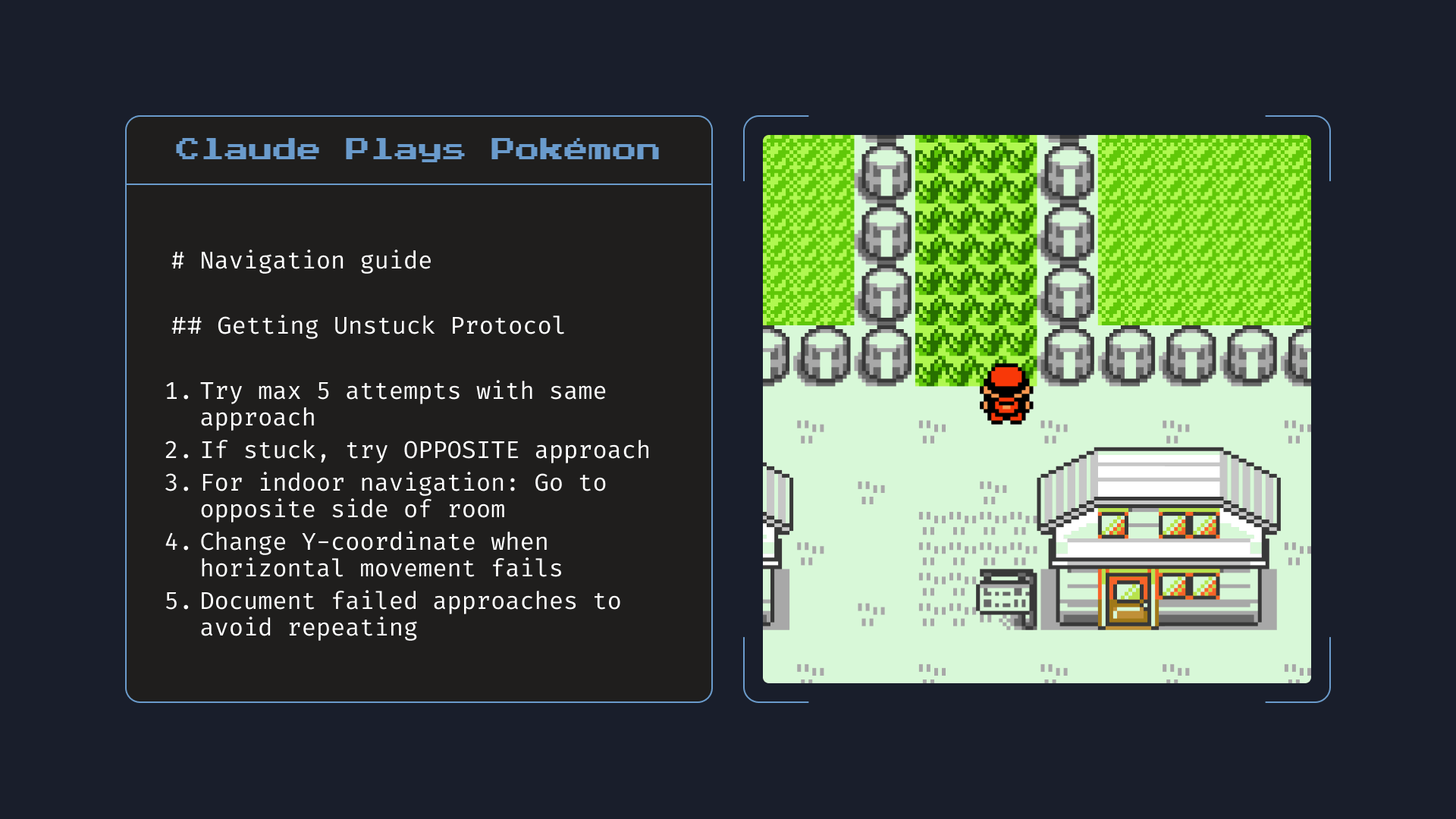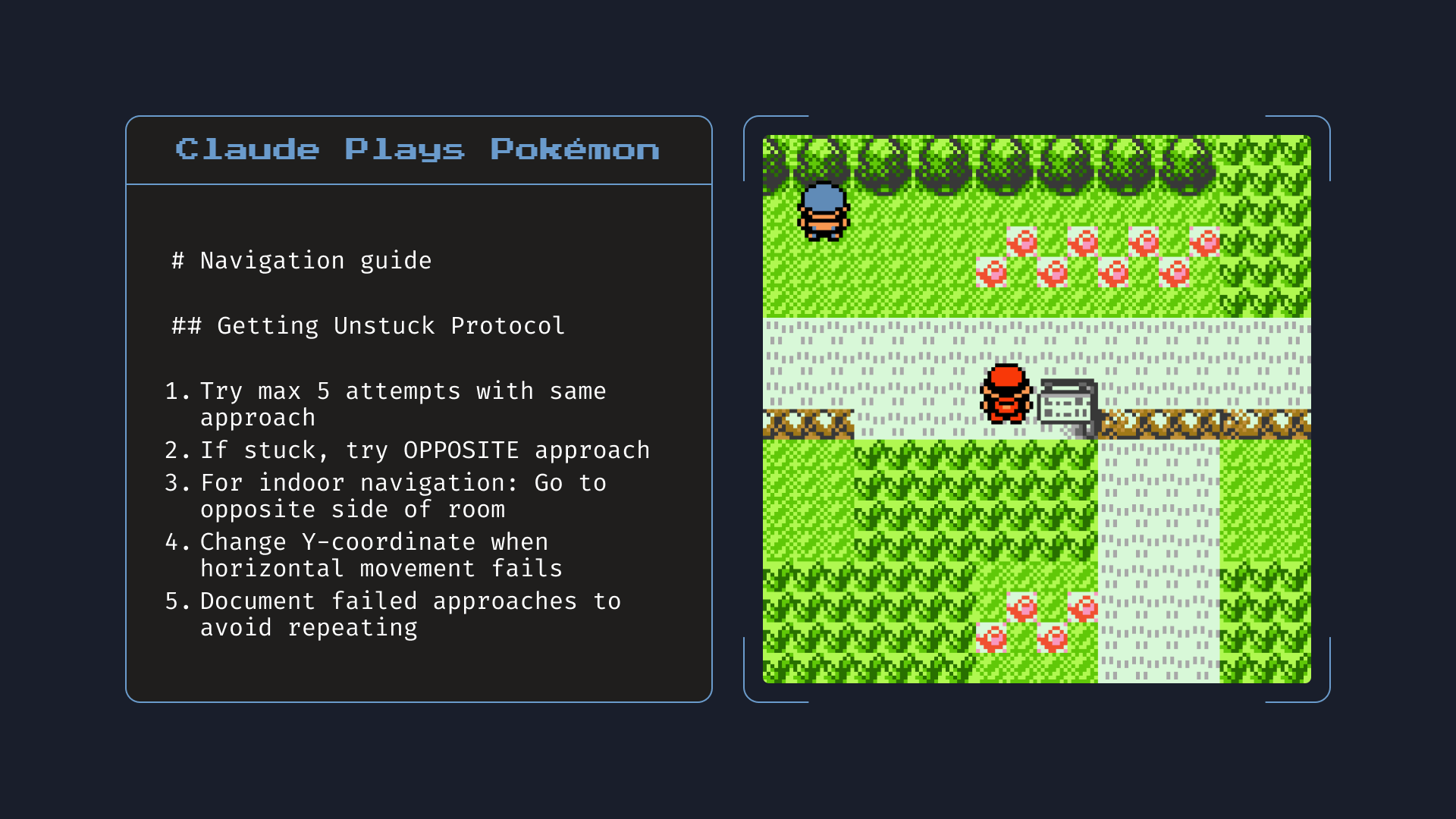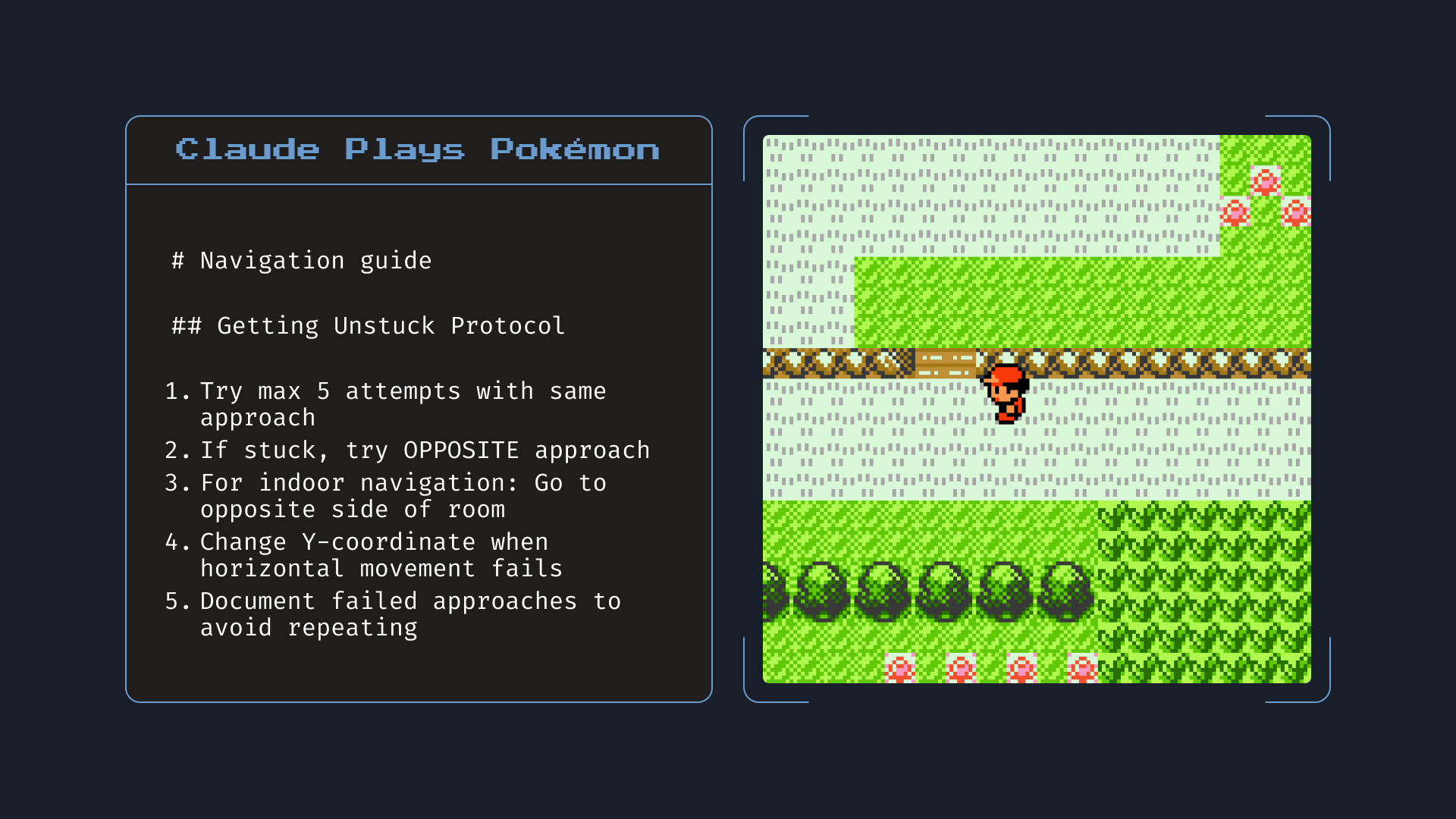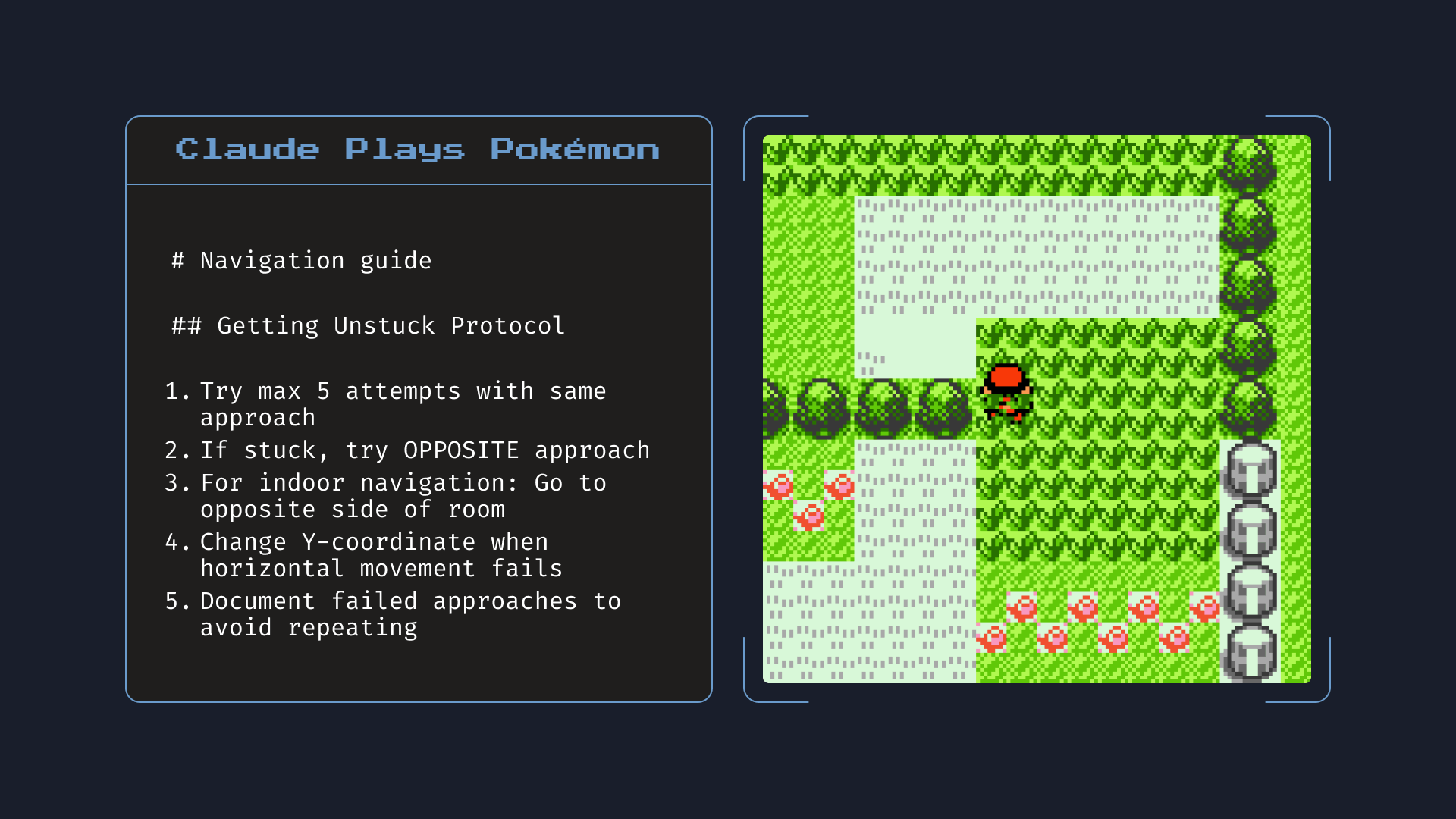
Learning to try again
Confronted with failure, traditional AI methods simply try the same approaches again and again, tweaking small actions. However, in a combinatorially large action space $O(|A|^T)$, this grows intractable for large $T$. We can observe that the agents will try different ideas – each different from the last – without ever discerning the true nature of the problem.
So what enables humans to solve these puzzles? After failed attempts, humans try semantically different methods. They don’t simply tweak a small action input (such as finetuning motor control skills in sports or for a robot), but rather pursue totally new directions, often requiring a long chain of inputs. Humans persistently try new ideas, building off their past failures.
One of the bottlenecks of current LLMs is that they have limited episodic memory in their context window or “scratchpad”. Imagine the LLM can remember its past $n$ attempts. Fundamentally, if the next attempt requires applying an insight from the last $n + 1$ memories, they will be unable to derive the new insight and end up getting stuck in a loop, thereby repeatedly trying the same unsuccessful strategies and getting stuck in a loop.
Pokemon speedrunning is an extreme example: players don’t simply seek to beat the game, but to beat it as fast as possible. They try over and over, seeking to improve their times by hundreths of seconds, constantly proposing new improvements and then implementing them. In stochastic games like Pokemon, they also have to adapt on the fly to the situations that arise, not merely overfitting to a specific sequence of button inputs. This is truly the capability we need in our models: they must not simply learn to “solve puzzles”, but to try and try again.
Learning to explore
A variety of exploration methods in RL – from entropy bonuses to epsilon-greedy and value ensembles – focus on ways to continually try new actions in search of the reward. This is great when the reward is dense: try something, get a reward, and update your value estimate. Then, try the new thing.
But humans don’t simply try combinations of inputs over and over again in hope of hitting the jackpot: they are optimizing in the direction of having fun! There is an aesthetic dimension of human play centered around curiosity: simply trying new ideas for the sake of seeing new outcomes. Even in the absence of a reward signal, humans will continually try new ideas for the purpose of learning and seeing new things (“gotta catch em all”). A human player might explore Meteor Falls not just to maximize state coverage, but because waterfalls are beautiful, or because they have a hunch that game designers hide secrets in aesthetically pleasing locations.
Moving towards scientific discovery, this distinction becomes crucial. Scientists will follow their own aesthetic principles, identify gaps in their knowledge, propose new hypotheses, and test them to learn new insights. They don’t merely brutally try all possible combinations (a la AlphaZero), but craft intelligently designed experiments. They don’t simply hallucinate ideas that sound right (at least, they hope not to), but have a precise notion of what is known and what isn’t, so they can plan to identify the unknown.
Building Pokemon games
Stepping back a bit, we might wonder: how do we even design games that humans will want to play?
Game creation is an open-ended design problem. Firstly, this is an interesting problem because games are fun and the video game industry is worth hundreds of billions of dollars. But moving forward, the creation of games is a microcosm for the methods of interaction agents will create for us (the humans) to experience the world, and the societal structures agents will design for us (the humans) to maximize human utility.
AI for game development
In particular, you could imagine that there are different tiers to which agents could assist in game creation:
- Asset generation: generative AI simply generates art or voice assets for a game which is otherwise human-made. Although boring (to me), this is already a valuable industry and is seeing applications in video games, Hollywood, and anime.
- AI-assisted: AI is used to assist conventional game developers to enable them to add more content faster, or otherwise enable “more of the same” for the status quo. It could help write code, in the same way LLMs assist programmers today.
- “Vibe coding”: AI enables ordinary humans who otherwise lack game development experience to bring their ideas to life, broadening the scope of games humans can release. We see new games from a broader set of creative designers, not the restricted set who know how to code.
- Fully autonomous: AI creates the whole video game – generating the story, experiences, new mechanics, etc. – offerring novel and infinite experiences for players.
I assume (1) and (2) to be uninteresting, merely “replacing” humans without extending the frontier of novelty. Without loss of generality, the topics I discuss below are intended to target how we can bring (3) and (4) to life: designing new creative experiences to improve human utility.

What makes Pokemon fun?
There are many theories for fun in game design, but fundamentally Pokemon is a simple game which rewards the player for steadily progressing in competence and discovering new stories in a fantastical world. You roleplay as a young adult in a world where complex responsibilities are abstracted away and you can focus on the fun of watching your Pokemon grow alongside you. There is a direct, satisfying path to progress that deepens the bond between player and Pokemon, leading to memorable stories that remembered for decades.

In 2014, over a million viewers contributed to a livestream, Twitch Plays Pokemon. Viewers input individual actions and a script converted them into inputs for a Pokemon game. While only being barely better than random (effectively a Ouija board), there were many memorable encounters, and viewers drew fanart and created stories for the caught Pokemon. Within the scope of the universe created by the game, deep stories and meaningful memories were built.
I also think there’s a lot to be said about replayability: in various roguelike games, you encounter new challenges and new scenarios. In Pokemon, players love new journeys across novel regions and stories. At their core, the best video games combine a fun, focused gameplay loop with an infinite story – and I think AI can help extend that.
That which enables agents to surpass humans

I’m personally super excited by the potential of agents to create novel gaming experiences which reshape what video games could look like from the ground up (note: not limited to video games :). Ultimately, the reason we’re betting on AI isn’t because it can act as a human or “merely” augment them – but that fully autonomous AI can be the driver of new worlds we could never experience in the human world. In particular, I think there are three exciting avenues uniquely suited for AI-driven development.
Infinite stories. One of the most immersive parts of video games (for players like me) is that there is a rich, vast story to discover – the land has a deep history full of characters to meet and histories to uncover, with new treasures behind ever corner – and no game embodies this as much as the vastness of World of Warcraft. However, of course, there is a limit to the story. The player inputs some sequence of actions $O(A^T)$ which maps to some story. As the game designer, it is simply intractable to create $O(A^T)$ different stories. But what if the world always adapted to the player? What if there was always the next door to uncover?
Infinite action space. One of the least immersive parts of video games is that you can only take the sequence of actions $|A|$ programmed by the designer. Unlike real life, where you can chase after anything you can dream, if the game lacks a mechanic, you must forgo it as a player. In the Pokemon anime, there are all sorts of career paths and ways of having fun with Pokemon – ranging from X to Y – but in the games, you can only follow a set number of actions with your Pokemon (mostly battling). While many games have offered infinite worlds (Minecraft, No Man’s Sky), none have truly offered the ability to do anything in the way a reactive AI could.
Personalization. Perhaps most powerfully, AI agents could create experiences tailored not just to player preferences but to their current emotional state and skill level. Dynamic difficulty adjustment exists in current games, but agent-driven personalization could go much deeper. The game could recognize when a player is frustrated and subtly adjust not just difficulty but the type of challenges presented. A player who enjoys puzzle-solving might find more cryptic ruins to explore; one who loves battling might encounter more trainer battles with increasingly sophisticated AI opponents.
Optimizing for engagement
So I think we have agents were are able to optimize to beat Pokemon games, and a promise that AI could be used for video game development. Today, LLMs lack the scaffolding and framework to actually build meaningful video games. But if we could figure out these pieces, I think we should start thinking about reinforcement learning for optimizing user engagement.
Designing interesting characters
Many v0 “AI for video games” approaches use an LLM chatbot for dialogue – but don’t fundamentally add to the experience. The chatbots are disconnected from the game, and the things they say aren’t reflected in the actions the player can take in the game. In contrast, many well-designed characters of the past have boring static dialogue – but they represent key pieces of the world building.
Games have to strike a balance between too much entropy (you can do anything, like roleplay with a chatbot) and too little (no different from watching a movie). Even human creatives generally need some seed to start with (a prompt or inspiration). While an LLM dialogue agent enables you to roleplay anything, if it doesn’t correspond meaningfully to one of the core gameplay mechanics, the character comes off as ungrounded and the player has no incentive to continue interacting with the character.
In particular, AI models are prone to sycophancy, which we recently saw plague GPT-4o. The player suggests something, and the AI agrees with the suggestion. While at a first glance this is great – hence why GPT-4o was sycophantic in the first place – this creates immediately useless world models.
Anyone who has tried using an LLM for Dungeons and Dragons has faced this problem: you tell the LLM that you cast fireball, and it tells you that you casted fireball. But what you need from the world model is the result of casting fireball – if I wanted to specify it myself, then I would have no need for the video game to augment my own imagination. What are the effects in the world? What are the reactions from the enemies? And what are the difficulties the player will encounter next?
Designing interesting levels
We need a curriculum of levels for the player to progress to, continually adding both new challenges and new stories to explore. In contrast to Perlin noise which generates infinite levels which look mostly the same, they must instead introduce novel semantic experiences to keep the player engaged and playing. In Pokemon, level design gates progression, teaches mechanics, introduces new characters, and continues the story – in the same way humans experience a variety of life experiences from childhood to adulthood.

In contrast to traditional methods of entropy injection that amount to uniform or Perlin noise, AI can now inject entropy in targeted ways: it can continually expand upon the story, introducing new characters that develop alongside the player, and add difficulty in precise ways to target the player. In this way, the models can generate a near-finite number of truly interesting levels to play (the “ultimate roguelike”).
A fun method for modeling difficulty is hindsight. The model creates a level and then tests it: players give feedback on the level difficulty, or otherwise we can think of this as summarized as the average “pass rate” of the player base. Now we have a mapping from level -> difficulty. Next time, we use hindsight: if I want a level with a certain difficulty, I train the AI to go the other way, from difficulty -> level. In this way, we can generate levels that exactly cater to the desired difficulty in the progression.
Designing for fun
Of course, while we’d like to have all these features (infinite replayability, personalization, …) what we ultimately care about is optimizing for fun. We’ve seen that recommendation systems like TikTok and YouTube have made tremendous strides in optimizing engagement metrics (they know what video to show you to keep you watching). So, how can we train the models to directly optimize fun?
Almost always, there is some disconnect between the feedback mechanism (eg, a thumbs up button) and the desired outcome (utility or fun). In the paperclip maximizer example, an AI told to make paperclips eventually converts all human atoms into paperclips. But what we really wanted was paperclips to maximize human utility (for the benefit of humans), not for the sake of having paperclips themselves. We’ve seen this be a real modern day problem with sycophancy above.

Ultimately, I am excited for novel product surfaces which minimize this gap between feedback and utility. If we could provide exactly the feedback we desire (fun), and use powerful reinforcement learning optimizers trained against it, I think we can ultimately produce new genres of games that expand the creative frontier and create novel human experiences.
Of course, once we’ve solved video games, we then want to tackle the problems in the wider world.