Decision Transformer
In this work (arXiv), we studied how offline reinforcement learning could be performed using conditional sequence modeling, the same approach behind language models and GPT.
Can RL algorithms be replaced with transformer-based language models? We’ve looked at this question with our work on Decision Transformer:
— Igor Mordatch (@IMordatch) June 2, 2021
Website: https://t.co/MBeQ1OPO4V
Code: https://t.co/Z71ycSMsFh
1/8 pic.twitter.com/ylBuwV6PN1
Example
The simplest way to think of Decision Transformer now (in the ChatGPT era) is as a chatbot:
- You start by saying: “You are an expert in X” or “You have an IQ of 140” (the target return).
- You then provide context to the situation, or give it a question (its observation).
- The model then responds to your question (its action).
This turned out to be a general emergent phenomena of large models trained on internet data:
Language-conditional models can act a bit like decision transformers, in that you can prompt them with a desired level of "reward".
— Phillip Isola (@phillip_isola) June 2, 2022
E.g., want prettier #dalle creations? "Just ask" by adding "[very]^n beautiful":
n=0: "A beautiful painting of a mountain next to a waterfall." pic.twitter.com/vu0NceTxAv
Here, we have:
- Target return: “very” ^ n
- Observation: the text prompt
- Action: the model’s generated image
Then for n=22: “A very very very very very very very very very very very very very very very very very very very very very very beautiful painting of a mountain next to a waterfall.”

Comparison to imitation learning
One of the crucial questions for us was whether to train on all the data (and condition on expertise), or only the high-quality expert subset: we named the latter “percentile behavior cloning” (%BC).
It turns out on the popular D4RL robotics benchmark, %BC was sufficient to achieve state of the art performance! However, in data-scarce settings such as the Atari benchmark, performance suffered drastically when throwing out data:
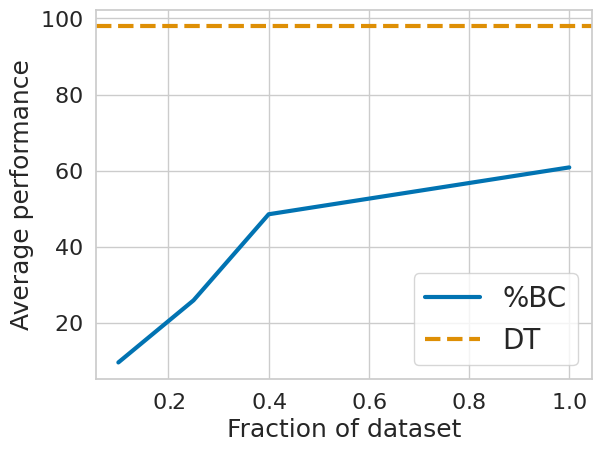
I think this is still a really interesting question, and continues to be an active topic of interest, as large foundation models are pretrained on vast low-quality data and then finetuned on high-quality subsets.
Follow-up work
There’s been a lot of interesting papers in this area, but just to highlight a few:
- Sep 2023 – OpenChat: Condition on either “expert” GPT-4 or “low quality” GPT-3.5
- Oct 2022 – Algorithm Distilation: Learn new tasks in-context via prompting
- Aug 2022 – Stable Diffusion: Conditions on an aesthetic score (also: CLIP-DT)
Supplementary links
Unaffiliated links:
- Dec 2021 – The Batch
- Jun 2021 – Yannic Kilcher
- Jun 2021 – SyncedReview
- Jun 2021 – The Gradient