Pretrained Transformers as Universal Computation Engines
In this work (arXiv), we found pretraining on language data could lead to nontrivially better performance on non-language tasks – early signs of multimodality inherent in large language models.
What are the limits to the generalization of large pretrained transformer models?
— Igor Mordatch (@IMordatch) March 10, 2021
We find minimal fine-tuning (~0.1% of params) performs as well as training from scratch on a completely new modality!
with @_kevinlu, @adityagrover_, @pabbeel
paper: https://t.co/DtWGJ0Afh7
1/8
Multimodal transfer
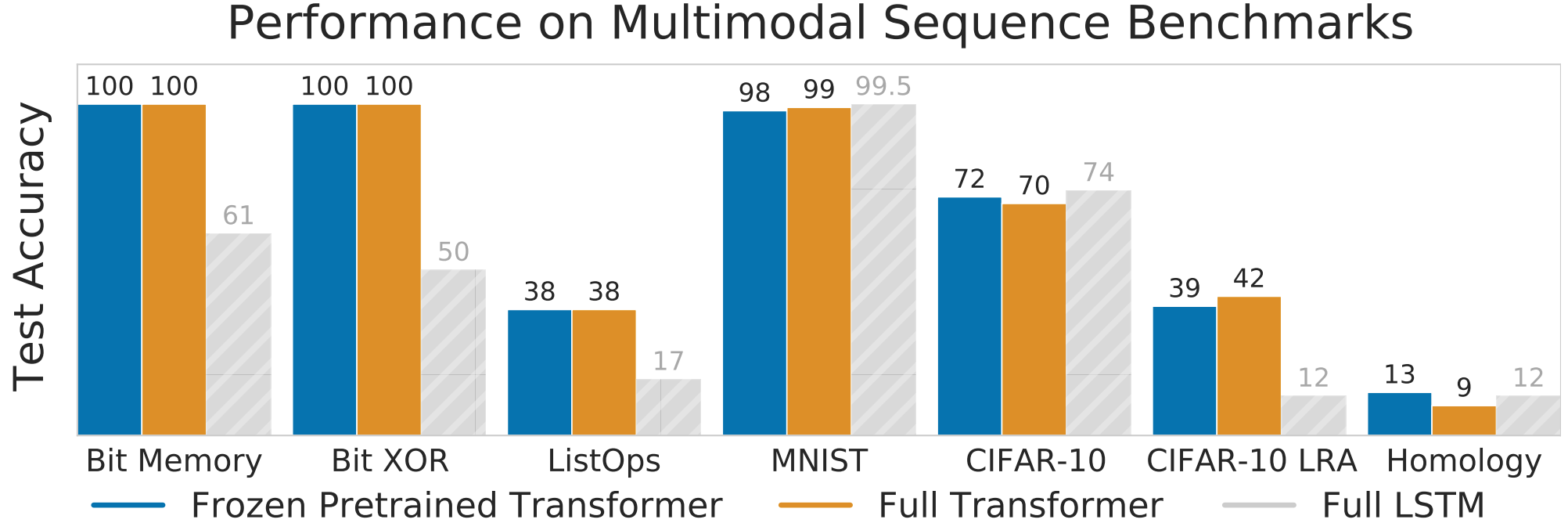
Our main result was that you can take GPT-2 (~= 100M parameters), and adapt it to a new modality by finetuning the input, output, and layer-norm parameters. This meant that we could transfer the bulk of the model (the attention and feedforward layers) to the new modality and achieve good performance without finetuning!
One implication of this is that you might think of the language model has having learned capabilities similar to the hippocampus: acting as a general, multimodal sequence processor. Then, perhaps you could use the base language model as the base for future adapters on top, performing reasoning in the space of language. Our initial result was far from this, but later work has pushed this capability, with LLMs such as GPT-4 and Gemini serving as the base for powerful multimodal capabilities.
Follow-up work
- Apr 2023 – LLaVA: Imbuing a language model with highly-performant vision capabilities
- Mar 2023 – PaLM-E: Turning a large language model into an embodied multimodal model
- Jun 2021 – Frozen: No longer necessary to finetune the layer-norm parameters
Supplementary links
Unaffiliated links:
- Jul 2021 – The Batch
- Mar 2021 – Yannic Kilcher
- Mar 2021 – VentureBeat